
著述转载于新智元
Scaling Law要撞墙了?
Anthropic联创Jack Clark反驳了这一说法:绝非如斯!
在他看来,面前的AI发展还远远没到极限,「统统告诉你AI进展正在放缓,大致Scaling Law正在撞墙的东说念主,王人是不实的。」
o3仍有很大的增漫空间,但接管了不同的方法。
OpenAI的技巧诀要并不是让模子变得更大,而是让它们在运行时,使用强化学习和非凡的缱绻能力。
这种「高声念念考」的能力,为Scaling开拓了全新的可能性。
而Jack Clark展望,这一趋势在2025年还会加快,届时,科技公司王人会启动将大模子的传统方法跟在磨砺和推理时使用缱绻的新方法相长入。
这个结论,跟OpenAI初次推出o系列模子时的说法完全吻合了。
在并吞时分,MIT的征询者也发现,接管测试时磨砺(TTT)技巧,能权臣提高LLM进行逻辑推理和贬禁止题的能力。

论文地址:https://ekinakyurek.github.io/papers/ttt.pdf
1
Scaling Law撞墙,十足错了
在他的新闻通信《Import AI》中,Clark对对于AI发展已到达瓶颈的不雅点进行了反驳。
博文地址:https://jack-clark.net/
比如OpenAI的o3模子,就评释了AI极大的发展空间。
在现存强劲基础模子之上,接管一种新方法——让大谈话模子在推理时「边念念考边奉行」,即测试时缱绻(test-time compute)。这种神气能带来广宽的薪金。
因此Clark展望,下一个合理的发展场地将是同期延迟强化学习(RL)和底层基础模子,这将带来更为权臣的性能进步。
这意味着,跟着现存方法(大模子scaling)与新方法(强化学习驱动的测试时缱绻等)的长入,2025年的AI进展相对2024年会进一步加快。
OpenAI知名征询员Jason Wei也示意,愈加关节的是,从o1到o3的高出也只是只用了3个月,这说明了在鼓励东说念主工智能范围发展方面来讲,强化学习驱动的推理延迟缱绻范式,会比预磨砺基础模子的传统延迟范式快得多。

这并非畅谈,Clark列举了不少o3的亮眼得益来评释他的不雅点。
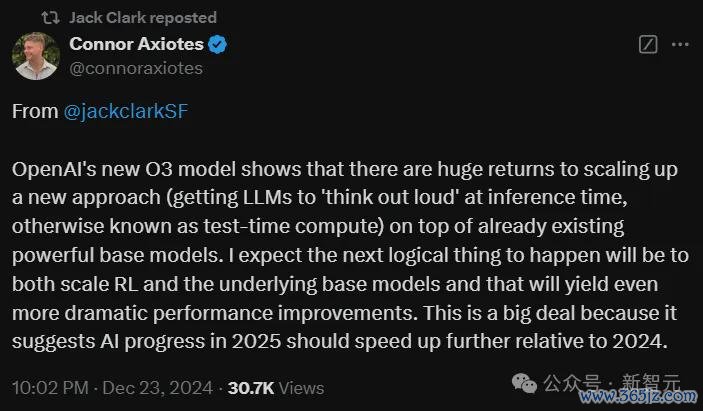
率先,o3灵验冲破了「GPQA」科学默契基准(88%),这彰显了它在科学范围进行知识推理息争答的能力。
它在「ARC-AGI」这一任务上的进展优于亚马逊众包平台(MTurk)雇佣的东说念主类使命者。
甚而,o3在FrontierMath上达到了25%的得益——这是一个由菲尔兹奖得主遐想的数学测试,就在几个月前,SOTA的得益仅为2%。
况兼,在Codeforces上,o3得回了2727分,名依次175。这让它成为这一极其贫穷基准上的最好竞技局势员之一。
1
模子资本将更难预测
Clark合计,大多数东说念主还莫得强项到改日进展的速率将会有多快。
「我合计,基本上莫得东说念主预猜度——从现在启动,AI进展将会有何等急剧。」
同期,他也指出,算力资本是急速进展中的一个主要挑战。
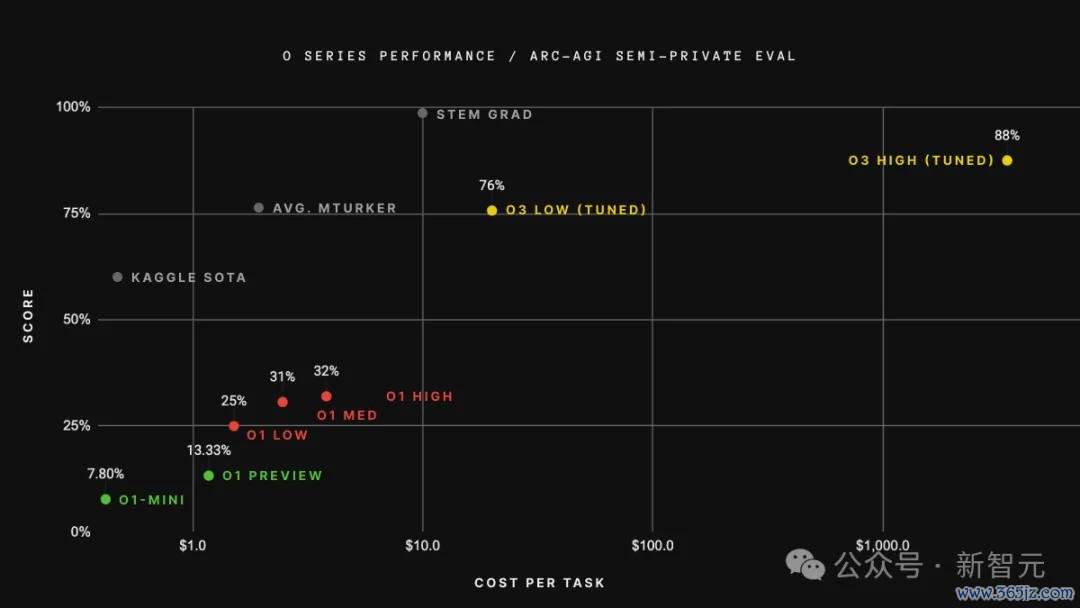
o3之是以如斯优秀,其中的一个原因是,它在推理时的运行资本更高。
o3的最先进版块需要的算力比基础版多170倍,而基础版的算力需求照旧超出了o1的需求,而o1自身所需的算力又超越了GPT-4。
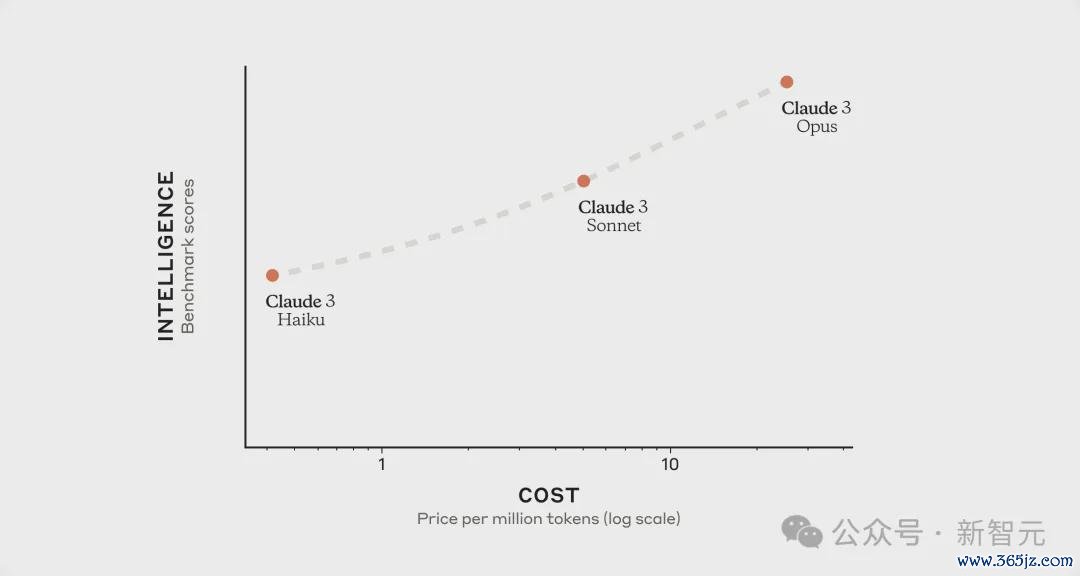
o系列模子的性能与资本
Clark解释说,这些基于推理延迟范式的新模子使得资本预测变得愈加贫穷。
昔时,模子的资本用度是很直不雅的,主要取决于模子的大小和输出长度。
但在o3这类模子中,由于其资源需求会字据具体任务的不同而变化,是以也更难直不雅地给出模子奉行任务时的破耗。
o3推理资本达新高
除了FrontierMath和Codeforces上的得益,o3在GPT Diamond Benchmar上,对于博士级的科学问题也拿到了87.7%,远高于各自范围博士群众70%的对等分。

ARC-AGI基准测试建立者、Keras之父François Chollet,将o3的性能称为「AI能力中令东说念主骇怪且蹙迫的阶跃函数增长」
而这背后付出的代价,等于运行o3极高的资本。
之是以会变成如斯高的资本,等于源于o3和其他模子处理问题神气的不同。
传统的LLM主要依靠的是检索存储方法,但o3处理问题时,却是靠及时创建新局势,来贬责不熟习的挑战。
Chollet示意,o3系统的使命旨趣,似乎和谷歌DeepMind的AlphaZero外洋象棋局势近似。后者会环环相扣地搜索可能的贬责有筹备,直到找到正确方法。
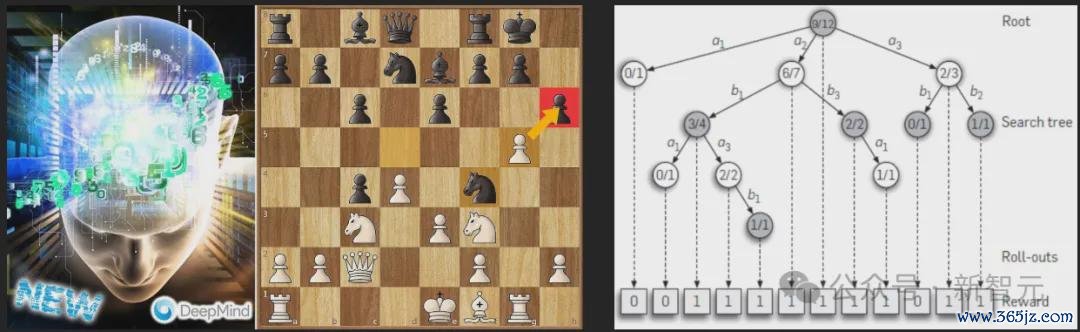
这个进程也就解释了,为什么o3需要如斯多的算力——只为单个任务,模子就需要处理多达3300万个token。
跟现时的AI系统比拟,这种密集的token处理资本,几乎是天价!
高强度推理版块的每个任务,运行用度约为20好意思元。
也等于说,100个测试任务的资本为2012好意思元,全套400个群众任务的资本则达到了6677好意思元(按平均每个任务破耗17好意思元缱绻)。
而对于低强度推理版块,OpenAI尚未清晰确切的资本,但测试骄横,此模子不错处理33至1.11亿个token,每个任务需要约1.3分钟的缱绻时分。

o3在ARC-AGI基准测试中必须贬责的视觉逻辑问题示例
1
恭候Anthropic的下一步
是以,Anthropic下一步会给咱们带来什么呢?
面前,由于Anthropic尚未发布推理模子(reasoning model)或测试时模子(test-time model),来与OpenAI的o系列或Google的Gemini Flash Thinking竞争,Clark的这一番预测,不禁让东说念主兴趣Anthropic的策划。
他们之前告示的Opus 3.5旗舰模子于今仍莫得确切音尘。
建立周期长达一个月,进程充满不笃信性
在11月,Anthropic CEO Dario Amodei曾阐明,公司正在建立Claude Opus的新版块。
起初,Opus 3.5定于本年发布,但自后Amodei再提到它时,只是说它会在「某个时刻」到来。
不外Amodei倒是清晰,公司最近更新和发布的Haiku 3.5,性能照旧跟原始的Opus 3相匹敌,同期运行速率还更快,资本也更低。
其实,这也不单是是Anthropic濒临的问题。
自GPT-4亮相以来,LLM的功能并莫得取得首要飞跃,这种停滞照旧成为AI行业内一种普遍的凡俗趋势。
更多时候,新发布的模子只是微细的高出,跟之前有一些微弱的死别。
建立更先进的LLM,为如何此复杂
在Lex Fridman的播客造访中,Amodei详备叙述了建立这些AI模子的复杂性。
他示意,仅磨砺阶段,就有可能会拖延数个月,还会需要无数的缱绻能力,用上比比皆是的专用芯片,如GPU或TPU。
预磨砺事后,模子将资格复杂的微调的进程,一个关节部分等于RLHF。
东说念主类群众会呕精心血地审查模子的输出,字据不同标准对其进行评分,匡助模子学习和修订。
接下来,等于一系列里面测试和外部审计,来查验模子的安全问题,频频是与好意思国和英国的AI安全组织相助。
总之,Amodei回来说念:天然AI的冲破在圈外东说念主士看来,像一个广宽的科学飞跃,但其实好多高出王人不错归结为枯燥和枯燥的技巧细节。
在此进程中,最贫穷的部分频频是软件建立、让模子运行得更快,而不是首要的观念高出。
而且,每个新版块模子的「智能」和「个性」,也王人会发生不行预测的变化。在他看来,正确磨砺模子与其说是一门科学,不如说是一门艺术。
即使信得过发布的Opus 3.5的性能有了进步,却也不及以评释其腾贵的运营资本是合理的。
不外,天然有东说念主合计Anthropic莫得紧跟推理模子的方法,照旧足以反馈LLM延迟的广宽挑战;但不得不说,Opus 3.5也并非毫无兴味。
理解,它匡助磨砺了全新的Sonnet 3.5,它照旧成为了面前市集上最受接待的LLM。
参考尊府:
https://the-decoder.com/ai-progress-in-2025-will-be-even-more-dramatic-says-anthropic-co-founder/
https://jack-clark.net/2024/12/23/import-ai-395-ai-and-energy-demand-distributed-training-via-demo-and-phi-4/
